
Mainframe Data Lineage: The Bridge Between Managing Today and Modernizing Tomorrow
Mainframes aren't going anywhere overnight. Despite the industry's push toward cloud migration and modernization, the reality is that many financial institutions still rely on mainframe systems to process millions of daily transactions, calculate interest accruals, manage account records, and run core business operations. And they will for years to come.
Modernization is the eventual reality for every organization still running on mainframe. But "eventual" is doing a lot of heavy lifting in that sentence. For many financial institutions, a full modernization effort is on the roadmap but years away — dependent on budget cycles, vendor timelines, regulatory considerations, and a hundred other competing priorities. In the meantime, these systems still need to be maintained — and that's where things get increasingly risky.
The hidden cost of "just making a change"
When a business requirement changes — say, a new regulation requires a different calculation methodology, or a product team needs to update how accrued interest is computed — someone has to go into the mainframe and update the code. Sounds straightforward enough. Except it's not.
Mainframe COBOL codebases are often decades old. They've been written, rewritten, and patched by generations of engineers, many of whom have long since left the organization. A single mainframe environment can contain tens of thousands of COBOL modules, each with hundreds or thousands of lines of code. Variables branch across modules. Tables are read and updated in ways that aren't always documented. Conditional logic sends data down different paths depending on record types, dates, or account classifications that may have made perfect sense in 1998 but aren't intuitive to anyone working today.
Before a mainframe engineer can write a single new line of code, they need to answer a deceptively simple question: What will this change affect?
And answering that question — tracing a variable backward through modules, understanding which tables get updated, identifying upstream and downstream dependencies — can take weeks or even months of manual investigation. One engineer we've worked with estimated that investigating the impact of a change takes substantially longer than actually making the change.
Why mainframe management feels like navigating a black box
The term "black box" gets used a lot in mainframe conversations, and for good reason. The challenge isn't that the code doesn't work — it usually works remarkably well. The challenge is that nobody fully understands how and why it works the way it does.
Consider what a typical investigation looks like without modern tooling. An engineer receives a request from the business: "We need to update how we calculate X." To comply, that engineer has to:
- Determine a relevant starting point for researching “X”, which may be a business term or a system term. This starting point, for example, could be a system variable in a frequently accessed COBOL module
- Open the relevant COBOL module (which might be thousands of lines long)
- Find and trace the variable in question through the code
- Identify every table and field it touches
- Follow it across modules when it gets called or referenced elsewhere, keeping track of pathways where the variable may take on a new name
- Map out conditional branching logic that might treat the variable differently based on account type, date ranges, or other factors
- Determine which downstream processes depend on the output
- Document all of this before they can even begin to assess whether the change is safe to make
Now multiply that by the reality that a single environment might have 50,000 to 500,000 to 5,000,000 modules. It's not hard to see why organizations describe their mainframe as a black box — and why changes feel so high-stakes.
The real risk: unintended consequences
The fear isn't hypothetical. When an engineer updates a module without fully understanding the dependencies, the consequences can ripple across systems. A calculation that looked isolated might feed into downstream reporting. A field that seemed unused might actually be read by another module under specific conditions. A change to one branch of conditional logic might alter outputs for an account type that wasn't part of the original requirement.
These kinds of unintended consequences don't always surface immediately. Sometimes they show up in reconciliation discrepancies weeks later. Sometimes a client calls and says, "My statement looks different this month." By that point, the investigation to find the root cause is just as painful as the original change — if not more so.
This is why many mainframe teams default to a conservative posture. They move slowly, pad timelines, and layer in extensive manual review. Not because they aren't skilled, but because the risk of getting it wrong is too high and the tools available to them haven't evolved with the complexity of the systems they manage.
A better approach: data lineage for mainframe management
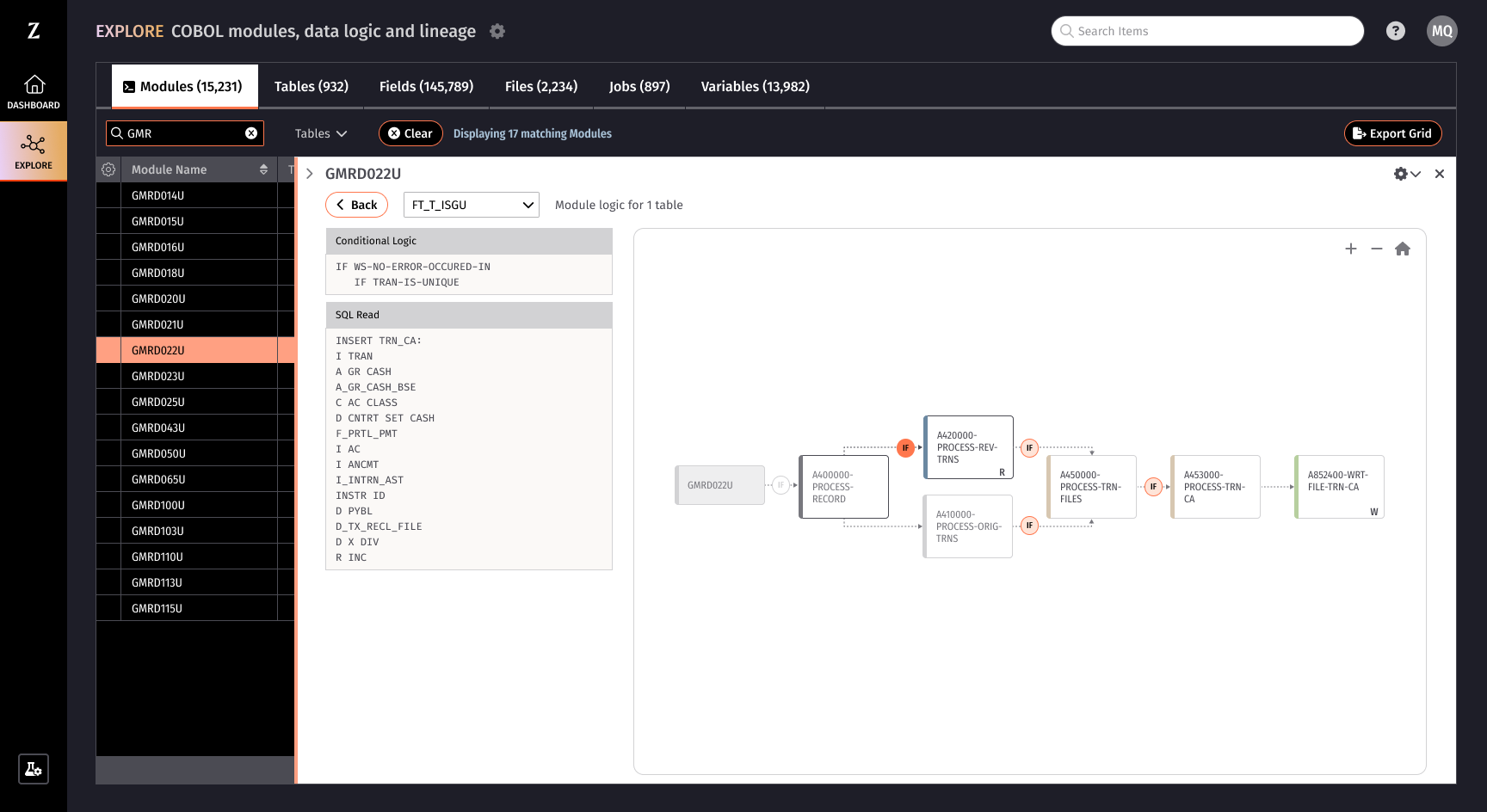
This is where mainframe data lineage changes the equation. Rather than manually tracing code paths and building dependency maps from scratch every time a change is requested, data lineage technology can parse COBOL modules at scale and generate a comprehensive, searchable view of how data flows through the system.
With data lineage in place, that same engineer who used to spend months investigating a change can now:
- Search for a specific variable, table, or field and immediately see every module that reads, writes, or updates it
- Trace the data path forward and backward to understand exactly where a value originates and where it ends up
- View calculation logic to understand the mathematical expressions and business rules embedded in the code
- Identify conditional branching to see where and why data gets treated differently based on record types or other criteria
- Understand cross-module dependencies to assess the full blast radius of a proposed change before making it
Instead of navigating thousands of lines of raw COBOL to answer a single question, the engineer gets a curated, structured view of exactly the information they need. The investigation that used to take months can happen in minutes.
Not just for modernization day — for every day between now and then
Much of the conversation around mainframe data lineage focuses on migration and modernization. And yes, lineage is critical for those efforts — but the value starts long before modernization kicks off.
Every time a business requirement changes, every time a regulation is updated, every time an engineer needs to write or modify code — they're navigating the same black box. Data lineage doesn't just prepare you for the future. It makes your mainframe safer and more manageable right now, during the months or years between today and the day you're ready to modernize.
For mainframe teams, it means less time investigating and more time executing. For risk and compliance leaders, it means greater confidence that changes won't introduce unintended consequences. For the business, it means faster turnaround on change requests without increasing operational risk.
And when modernization day does arrive, you'll be ready
Here's the other advantage of investing in data lineage now: when your organization is ready to modernize, you won't be starting from scratch.
Modernization isn't just about moving everything from the old system to the new one. It requires making deliberate decisions about what to bring forward and what to leave behind. Which business rules are still relevant? Which calculations need to be replicated exactly, and which should be redesigned? Which data paths reflect current requirements, and which are artifacts of decisions made decades ago?
Without lineage, those questions send teams back into the same manual investigation cycle — except now they're doing it across tens of thousands of modules under the pressure of a migration timeline. With lineage already in place, your team walks into modernization with a comprehensive understanding of how the current system works, what it does, and why.
And the value doesn't stop at cutover. Post-migration, lineage gives you a baseline for reconciliation. When the new system produces a different output than the old one — and it will — lineage helps you trace back to the original logic and understand why the results differ. Was it an intentional change? A missed business rule? A calculation that was carried over incorrectly? Instead of guessing, your team can pinpoint the source of the discrepancy and resolve it with confidence.
The mainframe isn't the problem. The lack of visibility is.
Organizations that rely on mainframes aren't behind — they're running proven, reliable infrastructure that processes critical transactions every day. The challenge has never been the mainframe itself. It's that the tools and processes for understanding what's inside it haven't kept pace with the complexity of the systems or the speed at which the business needs to evolve.
Data lineage closes that gap. Whether modernization is two years away or five, understanding what's inside the black box isn't something you can afford to wait on. Your teams need that visibility today to manage changes safely — and they'll need it even more when the time comes to move forward.
Zengines' Mainframe Data Lineage solution parses COBOL code at scale to give your team searchable, visual access to the data paths, calculation logic, dependencies, and business rules embedded in your mainframe.

You may also like

At industry conferences this year, I’ve spent dozens of hours inside conversations with CEOs, CDOs, CIOs and operating executives across financial services. When I ask what’s keeping them up at night when it comes to their data, the answer is remarkably consistent: data access. They want data more accessible, faster, in more usable form, in more places, with fewer gatekeepers.
What's notable is what they don't ask for. Not trustworthiness. Not audit-ability. Not the ability to defend a number to a regulator without calling three people first. Access is the ceiling of the conversation, and honestly, that makes sense. In large financial enterprises built on decades of legacy applications, murky integrations, and pipelines that nobody fully documented, just getting the data somewhere useful is still a meaningful achievement.
The problem is that "getting the data" is already more complicated than most leaders realize. The moment data leaves its source system, decisions are being made about it. Decisions that quietly change what it means. And if you don't know those decisions were made, you don't know what you're actually looking at.
That's where lineage comes in, and why it matters even before you get to the outcomes leaders should be asking for.
Below, I’ll walk through (1) what “access” really delivers, (2) the abstraction layer hidden inside every extraction, (3) the compounding problem of “data derivatives”, (4) a concrete example – encoding and precision – where this gets expensive, and (5) what business leaders should be asking for instead.
What “Data Access” Really Delivers
When a business team asks for access to data, they almost always receive something that has already been processed for their consumption. Someone – usually a data engineer or database administrator – sat down with the source system and made a series of decisions:
- Which tables matter for this use case
- Which fields to expose
- How to filter, aggregate, or join the records
- Which technical artifacts to strip out (temp tables, system metrics, audit fields that don’t translate to business meaning)
These decisions are reasonable. Business consumers don’t want raw operational data; they want something readable without extraneous noise. But every one of those decisions encodes logic and judgment that doesn’t travel with the data. The output looks complete – and to the business user, it looks like the source of truth – but it is already an abstraction.
The Extraction Event Is a Translation Event
I find it useful to think of an extraction as a translation. Someone translated the operational reality of a data storage system into a business-readable view. Like any translation, choices were made: what to keep, what to drop, how to render concepts that don’t map cleanly across contexts. And like any translation, those choices can quietly change the meaning.
When a business leader looks at the extracted view, the assumption is usually that the data was “moved and shifted” – that is, copied with fidelity. That assumption is possible. In my experience, it is also highly doubtful. Logic gets applied at the moment of extraction, and unless someone deliberately captured and shared that logic, it is invisible by the time the data reaches a dashboard.
Abstractions of Abstractions: How Data Derivatives Compound the Problem
Here is where it gets harder.
Once an extracted data set exists, other people start using it. And why wouldn't they? There is already a data access path. The alternative - forging a new data access path - is the full corporate yellow tape headache: hunting for a charge code, filling out a technical work request that Business can’t quite decipher, watching that ticket age in a queue, and depending on legacy data SMEs who left the company in 2019. The extracted data set skips all of that. Already shaped for consumption, already lightly documented, already trusted by some peer team who vouched for it in a meeting six months ago. So the next team builds a report off it. Or creates a derivative data set for their own use case. Or both. What they don't realize is that the easy path and the right path may not be the same one.
They use it because it’s available and easier than starting from scratch – it’s already shaped for consumption, already lightly documented, already trusted by some peer team. So they build a new report off it. Or they create a derivative data set for their own use case. Or both.
That derivative is now an abstraction of an abstraction. The further you move from the originating system, the more layers of unrecorded judgment sit between the business decision and the operational event the data was supposed to describe. By the third or fourth hop, the question “where did this number come from?” can be genuinely difficult to answer – even for the team that produced the report.
A Concrete Example: How Encoding and Precision Quietly Rewrite Your Data
Let me make this concrete with an example I keep encountering.
When data is moved between systems, engineers make practical choices about how to package it. One of those choices is how to handle numeric precision. A value originally stored at six decimal places in the source might be packaged at four, or two, depending on what the receiving system supports – or simply what the engineer is most familiar with.
In some industries, that’s fine. In financial services, insurance, and healthcare, it is often not fine. A decimal place in an interest rate, a reserve calculation, or a pricing model can represent material variance. Once precision has been silently reduced, the data is no longer the real data – it is an approximation that looks identical to a casual reviewer. The business consumer assumes they’re working with the underlying record; in reality, they’re working with a rounded version of it that was reshaped during packaging.
This is exactly the kind of change that lineage is built to surface. Without lineage, you can’t tell that anything happened. With lineage, the precision change is documented, traceable, and reviewable.
Why Regulated Industries Can’t Afford to Skip Data Lineage
Regulatory frameworks have been ahead of business intuition on this point. BCBS-239 requires banks to demonstrate the accuracy, completeness, and timeliness of their risk data – which is impossible to defend without lineage. ORSA and Solvency II require insurers to substantiate the data flowing into solvency and capital calculations. None of these frameworks ask whether you have access to the data. They ask whether you can prove what the data is and how it got there.
For institutions operating under these regimes, lineage isn’t a nice-to-have analytics enhancement. It is the substrate that makes the rest of the data conversation defensible.
What Business Leaders Should Be Asking For Instead
If “give me access to the data” is the wrong ask on its own, what’s the right one? In my view, business leaders should be asking three questions every time a new data set lands on their desk:
- Where did this data originate, and what happened to it between then and now? Not a verbal summary – a documented path that is understandable in Business terms.
- What decisions were made during extraction or packaging that could have changed the meaning of the values I’m looking at? Especially around encoding, precision, filtering, and aggregation.
- If a regulator or auditor asked me to defend this number tomorrow, do I have the evidence trail to do it? If the answer is “we’d have to go find the engineer who built this,” the answer is no.
These questions don’t replace the access conversation – they extend it. Access is the entry point. Lineage is what makes access trustworthy.
A Final Thought
The reason business teams don’t ask for lineage isn’t that lineage doesn’t matter. It’s that the absence of lineage rarely announces itself. The data looks fine. The dashboard renders. The report mostly ties out. The risk lives in the assumptions you didn’t know you were making about what the data went through to get to you.
If your business teams are only asking for access, you have a gap – and in legacy environments where decades of undocumented logic sit between the source and the report, that gap is widest. The fix is to start asking for lineage too.
See Contextual Data Lineage in Action
Zengines Contextual Data Lineage is built for the environments where the lineage gap is widest – large financial enterprises with critical business logic locked inside COBOL, RPG, PL/1, and AS/400 code. We extract that embedded logic, make the data path visible, and give your teams the evidence trail they need to defend their numbers to auditors, regulators, and themselves.
If you’re working through a BCBS-239, ORSA, or Solvency II mandate, a planned mainframe migration, or a growing trust gap between your business teams and the data they consume, we’d like to hear about it.


In 2006, British mathematician Clive Humby coined a phrase that would define the next two decades of enterprise thinking: "data is the new oil." A decade later, in May 2017, The Economist made it a cover story – declaring data the world's most valuable resource and arguing that the data economy demanded a new approach to competition itself.
Twenty years after Humby first said it, the metaphor has only become more apt. What's changed is the catalyst. AI – and specifically the broad accessibility of large language models – has turned the abstract value of data into something organizations can now act on, at scale, in their actual operations. Every enterprise executive and Board member conversation I'm in today centers on the same question: are we positioned to scale value from AI?
The honest answer for most financial services enterprises is: not yet. And the gap isn't model selection, infrastructure, or use case prioritization. The gap is data readiness.
This post lays out what "AI-ready data" actually means in an enterprise context and the two capabilities that determine whether you have it.
What "AI-Ready Data" Actually Means
Strip away the hype, and AI-ready data comes down to two things:
- The data has to be available – meaning it can be moved, accessed, and used by modern systems regardless of where it originally lived.
- The data has to be trustworthy – meaning you know and can explain what it is, where it came from, and what business logic shaped it.
Both sound obvious. Neither is easy. And in older institutions with legacy applications – like in financial services – where institutions are sitting on decades of data stored across generations of systems, both require deliberate enterprise capability.
Pillar 1: Data Usability
Decades of preserved data only retains its value if the organization can keep it working. That means the ability to move it, transform it, and deliver it in a form whatever comes next can ingest; a new platform, a new analytics layer, an AI tool. Without that organizational capability, preserved data becomes stranded data.
Making data persistently usable across system changes is a data migration problem.
For institutions that have spent decades preserving customer records, transaction histories, account positions, and policy data, that preservation only translates into value if the data remains usable today. Not in the form it was stored in 30 years ago. In the form your current systems, your current analysts, and your current AI tools can ingest.
That's where data migration comes in – and where I'd encourage every executive to reframe how they think about it.
For most of the last 20 years, data migration has been treated as a one-time, project-bound activity tied to a specific systems initiative. A core conversion. A CRM rollout. An acquisition. A means to an end – the job had a start date and an end date, and once the data was "moved," the team and tools were disbanded.
That framing made sense in a world where systems changed every 10 to 15 years. It doesn't make sense anymore. The pace of modernization – driven by cloud adoption, AI tooling, vendor consolidation, and M&A – means data is constantly in motion. Treating each move as a bespoke, manually-staffed project is what makes modernization slow, expensive, and risky.
We built Zengines' data migration platform on a different premise: that data migration is a change capability, not a one-time activity. It's how you ensure your data remains an asset across every system change you'll make in the next 20 years – regardless of source format, target schema, or technology stack. That's what makes the underlying asset AI-ready: portable, repeatable, accessible.
For ISVs, BPOs, and MSPs onboarding clients onto modern platforms, the same logic applies and the economics are even more direct. Data conversion is, as I've argued before, a CEO-level concern – every client conversion that takes six months instead of six weeks is revenue deferred. Our platform compresses onboarding timelines by up to 80% by automating the manual work of mapping, profiling, transforming, and moving.
Pillar 2: Data Trustworthiness
Trustworthiness has many dimensions; data quality, governance, compliance controls. But none of those can be properly established without first answering a more fundamental question: what does this data actually represent, what logic produced it, where did it come from, and why does it look the way it does? That's a lineage problem, and it has to be solved before the rest can follow. In legacy-heavy environments, it's even harder to answer.
Trustworthiness matters on two distinct fronts:
First, the consumers of AI outputs; analysts, risk managers, portfolio teams; will act on what they trust. AI outputs will certainly attract interest; but that confidence erodes the moment someone is in a hot seat and can't explain a result, defend a decision, or reconcile an inconsistency. Without traceable source logic, that moment is a matter of when, not if.
Second, regulators are already examining AI model inputs. Under regulatory frameworks like BCBS 239, ORSA, Solvency II, "we trained on legacy system output" is not an explanation. The explanation lives in the code.
This is where data lineage matters, and where financial services has a particular challenge.
A significant portion of the data that drives banking, insurance, and asset management still flows through legacy systems – mainframes and the codebases that sit on them: COBOL, RPG, PL/1, Assembler. These systems weren't built to expose their logic to outside observers. The data they produce reflects calculations, conditional branches, and business rules that were written decades ago, often by people who have long since retired. When a CDO asks today, why does our risk exposure calculation produce this number?, the answer is buried in code that no current analyst can quickly read end-to-end.
At one Fortune 100 financial institution we work with, the environment includes nearly 100,000 COBOL modules. That's not unusual for an enterprise of that scale. It's the norm.
Without a way to expose the logic embedded in those systems, AI initiatives that touch this data are flying blind. You can train a model on the outputs, but you can't explain the outputs. You can move the data, but you can't verify what it represents. For regulated institutions, that's a non-starter.
This is the problem Zengines' Contextual Data Lineage solves. It parses legacy code – COBOL, RPG, PL/1 – and surfaces the business logic embedded inside: calculations, branching conditions, data origins, downstream dependencies. Instead of waiting nine months for a subject matter expert to reverse-engineer a single business rule, an analyst can answer the question in minutes. That's what makes legacy data not just movable, but explainable. And explainability is what makes data AI-ready in a regulated environment.
Why This Matters Now
The institutions making the most progress on AI right now aren't the ones with the most ambitious model strategies. They're the ones who've done the unglamorous work on the foundation – ensuring their data is preserved across system changes, and that the logic embedded in their legacy systems is documented, understandable, and ready to be replicated or retired with confidence.
That foundation is what allows AI initiatives to move from pilot to production to scaled value. It's what allows risk teams to validate AI-driven outputs against regulatory expectations with confidence. It's what allows finance and operations teams to actually trust what AI is telling them.
The window to build this foundation is now. Every quarter spent treating data migration as a project – or treating legacy code as an unsolvable black box – is a quarter of AI value deferred.
Two Capabilities, One Outcome
AI-ready data isn't a destination. It's the natural outcome of two capabilities working together: the ability to move data through any transformation or modernization without losing it, and the ability to understand the logic that defines what the data means over time and pathways.
Zengines was built to deliver both. Our data migration platform makes data preservation and utility a repeatable, AI-accelerated capability. Our Contextual Data Lineage exposes the logic locked inside legacy systems so analysts, auditors, and AI tools can use it with confidence.
If your organization is wrestling with how to position your data for AI – whether that's preserving decades of records through modernization, or making your legacy systems explainable to your CDO, CRO, or your regulators – we should talk.
See how Zengines accelerates the path to AI-ready data.
.png)
BOSTON, MA - May 8, 2026 - Zengines, Inc. today announced it has won Best of Show at FinovateSpring 2026, selected by audience and judges vote at the premier fintech demo event. The conference brought together more than 1,200 senior-level fintech and financial services executives - including 600+ from banks, credit unions, and financial institutions - to evaluate 50+ live product demonstrations.
Finovate recognized Zengines for its Contextual Data Lineage solution, citing the platform for "modernizing off mainframes without losing critical logic, satisfying auditors faster, and making legacy systems searchable so transformation and compliance don't stall."
Why it matters
Every financial institution running COBOL, RPG, or PL/1 has the same problem: the people who built those systems are retiring, regulators are asking questions the systems can't answer, and no one knows what a modernization program will actually touch until it's too late.
Zengines changes what's possible. Ask a plain-English question about your data. Get a complete, sourced answer - grounded in the actual logic embedded in the code, not a guess. Regulatory questions that took months get resolved in days. Migration risk gets quantified before work begins, not after.
Zengines is already working with a Fortune 100 financial institutions to navigate applications written in COBOL and RPG, each with more than tens of thousands of COBOL modules, cutting analysis time to minutes rather than months of manual research methods.
"Legacy system modernization has traditionally required a leap of faith - guessing what's in the code before you start rewriting it. We don't accept that. Contextual data lineage replaces guesswork with answers: regulatory questions resolved in days, business logic preserved through migration, and compliance that doesn't hinge on institutional memory. We're proving there is a better way to manage today and modernize tomorrow." - Caitlyn Truong, CEO and Co-Founder, Zengines
Watch the demo replay
About FinovateSpring 2026
FinovateSpring is the US West Coast's premier fintech showcase, bringing together innovators and banking decision-makers to shape the future of financial services. Best of Show awards are determined entirely by audience vote, with attendees rating companies on demo quality and potential impact.
About Zengines
Founded in 2020, Zengines is an AI-powered platform purpose-built for financial services data lineage and migration. The company helps financial institutions understand what is actually inside their legacy systems - so they can satisfy regulators, manage operational risk, and modernize without guesswork. Learn more or request a demo.
Subscribe to our Insights
.png)

Accelerate and de-risk data projects by 80%.
